1 What is a Compiler?
1.1 Introduction
Welcome to CMSC 430, An Introduction to Compilers. Ostensibly this class is about compilers. It’s right there in the name. And yes, this course is very much about compilers, but really this course is about the design and implementation of programming languages. Compilers just happen to be one possible implementation strategy.
1.2 What is a Programming Language?
It is worth taking a moment and thinking about what exactly is a programming language? At this point in your life, you’ve probably used several different programming languages (we make you, after all). You’ve written programs in C, Java, Rust, OCaml, and likely several others. You’ve maybe used these things without every really reflecting on what they are. So do that for a moment.
What did you come up with?
I start every semester by asking students to answer this question and I get a variety of responses. Here are a few:
"is an interface with the computer"
"is a human readable way to create computer instructions"
"is a combination of syntax and semantics for creating behavior"
"a formal language (a set of strings) that can describe any Turing machine"
"is a toolbox that prioritizes certain methods of solving problems"
"is a mechanism for communicating computational ideas with other people"
Let’s try to synthesize something coherent out of these different perspectives.
Formally speaking, we can characterize a programming language by the
set of programs in that langauge. For example, we might say the C
programming language is, at its core, the set of all possible C
programs that could be written. This is the way one might
characterize a language in a theory of computation course. If we
wanted to rigorously define this set, we could provide a formal
recognizer such as a finite automaton or even a Turing-machine that
given a string, determines membership in the set of programs. This
aspect of a language we call its syntax: it
concerns the rules governing the formation of phrases in the language.
While important, syntax is not the end-all of a programming language,
in fact it really just the start of where the rubber meets the road.
For example, when writing a C program we mostly don’t care about
whether the thing we are writing is or is not in the set of C programs
—
There are many ways we might define the meaning of a program, and therby define the semantics of the language. We could give examples, e.g. "3 + 4 computes 7." We could informally describe what expressions of the langauge should compute, e.g. "‘n + m‘ computes the sum of n and m". We could make more rigorous formal definitions, appealing to mathematical notation and concepts. We could write a program (perhaps in a different language) that interprets expressions and computes their meaning. Typically some combination of all of these approaches are used.
Putting it all together, we can concisely define a programming language as follows:
A programming language is a formal language for expressing computations, with rules for what programs look like (syntax), and rules for what those programs mean or do when run (semantics).
But all of this defines what a programming language is, which is not the same as realizing that definition. For that we need to implement the language, meaning we need to construct a universal program that given any element of the language, it carries out the computation defined by the meaning of that program.
Of course this is all a very formal view of what a programming language is. Arguably more important are other more human-centered perspectives. A programming language is a human-made language for conveying computational ideas, both to machines and to other people. Programming language design can enable (or prohibit) effective expression of those ideas.
Programming languages have evolved over time from being very concerned with low-level, machine-oriented details to higher-level abstractions, freeing the programmer from those low-level details and often making it easier to write better programs. Language design can eliminate whole classes of mistakes that might be possible in other languages.
1.2.1 What is a Compiler?
All that and no mention of compilers. OK, so if we have a sense of what a programming language is now, what is a compiler? You’ve probably used several before but maybe never reflected too deeply on what exactly they were. Take a moment and think about what being a compiler means to you.
Compilers are a particular implementation strategy for realizing a programming language. At their heart, compilers employ a fundamental technique of computer science for solving problems, they perform a reduction. In order to compute the meaning of a program, a compiler translates that program into a program in a different language and then uses the realization of that language to compute the answer to the original program. This is in contrast to an interpreter which computes the meaning of a program directly.
There’s something lurking here that may be causing you some discomfort. Let’s say you have a compiler that translates programs in language A into programs in language B. How does that help you run your language A programs? Well you just run your language B program and what it computes will be the thing that the language A program computes (assuming the compiler performed a correct translation). But you may be asking yourself, how do you compute the language B program!? It’s not clear you’re any closer to the thing you want. Well, maybe you have a compiler from B to C. And D to E. Uh oh. OK, well maybe at some point you have an interpreter. Let’s say you have an interpreter for langauge E. After chaining all these compilers together, you have a thing you can run directly by feeding it the E interpreter and compute the result which is actually the result of the original A program. Pfew.
But wait... the program that interprets E programs, it has to be written in a language. Let’s say it was written in F. How do we run F programs? Maybe we compile to G, H, I, K. Maybe there’s an intpreter for K, written in L... Oh dear. We still have this seemingly endless regress because in order to compute programs in one langauge we have to know how to compute programs in another language: that other language is either the target language of some compiler or the implementation language of some interpreter. Where does this all bottom out?
One concrete answer to this question is: it bottoms out at the machine language of your computer and its CPU. Eventually we hit a point where there’s a compiler that translates from some language into machine code, or there’s an interpreter that’s written in machine code (or we can compile the interpreter into machine code, etc.). The machine code is just another programming language, but it’s a language that has an intrepreter implemented in hardware. It runs programs by physically carrying out the computation of the program, thus providing a foundation for building up our computational house of cards. Ultimately, all of the computations your computer is doing are carried out at the level of machine code intepreted by the CPU. So even though you may be running Java, Python, or Rust code, what’s actually happening is the CPU is running machine code. But here’s the magical thing: it doesn’t really matter. Once you know that you can run, say, Java code on your computer, you can view Java as the foundation if you want. If you wanted to develop a new programming language, you could write a compiler that targets Java or you could write an intepreter in Java. Your new language could run anywhere that Java can run (which is essentially anywhere). One of the great contributions of programming languages is that it allows us to build the world we want to live in and leave the old one behind. This is in fact why compilers were invented in the first place.
An important observation to make: programming languages exist independently of their implementations. Java is not ‘javac‘. C is not ‘gcc‘ (or ‘clang‘). Haskell is not ‘ghc‘. Compilers are a particular implementation strategy for realizing a programming language. Sometimes languages get conflated with their implementations. And sometimes we go further and conflate properties of the implementation with the language itself. This leads to people saying things like "Python is an interpreted language; C is a compiled language." Python is not an interpreted language, rather it’s most well-known implementation is an interpreter. Compilers for Python exist as do interpreters for C.
1.2.2 What will be do in this course?
We are going to study how to implementat a programming language by making our own programming language. In particular, we are going to build a compiler for our language.
The language we are going to build is a modern, high-level general-purpose programming language. It will have features like:
built-in datatypes including integers, boolean, characters, strings, vectors, lists, and user-defined structures
first-class functions
pattern matching
memory safety
proper tail calls
automatic memory management
file I/O
Our compiler is going to target x86-64 machine code, meaning that programs written in our high-level language can be run on any system capable of running x86-64 code, either natively in hardware, or through software simulation (e.g. Rosette on Apple Silicon Macs). x86-64 is one of the most ubiquitous instruction set architectures in use today. It’s also quite large, complicated, and old, with some design constraints that date back over 4 decades as it has evolved from its 16-bit precursor first released in 1978. The choice of x86-64 as the target of our compiler is largely an arbitrary one. We could easily have picked another instruction set architecture, like ARM64, or targeted an intermediate representation like LLVM IR. In choosing x86-64 we get a messy, "real", and bare-bones, low-level view of computation and moving to any of these other similar settings would be fairly easy to do. Alternatively, we could have targeted a higher-level language such as C or Rust, or even JavaScript or OCaml. The more high-level the language, the easier it will be to serve as a target for the compiler, especially when the target language’s semantics are close the source language’s. Doing so could certainly be interesting, but it would illuminate compilation only down to the level of abstractions of the target language. By going all the way down to machine code, we are able to understand the implementation of our high-level language features completely down to the actions of the CPU. There will be no more mystery.
In order to side-step getting bogged down in making design choices, we are going to implement (a subset of) an existing high-level langauge called Racket. Racket is a member of the Lisp family of langauges, a descendent of the Scheme programming language, and a close cousin of OCaml, which you’ve previously studied. This is largely an arbitrary choice. We could have picked any programming language to build a compiler for. In choosing Racket, we get a mature, well-designed language with a minimal, easy to parse syntax and a well-understood and clear semantics that has features representative of many modern high-level programming languages such as OCaml, Java, Python, JavaScript, Haskell, etc. If you can write a compiler for Racket, you are well-equiped to write a compiler for any of those or similar languages, or even to design your own new language.
We will us an incremental approach to study and build compilers, meaning we will start by specifying and implementing a very small subset of Racket. Once specified, implemented, and tested, we will enlarge the set of programs in the langauge, typically by adding some new langauge feature. Doing so necessitates revisiting the specification and implementation to handle this extended set of programs. And then we rinse and repeat, growing the language from something trivial into a fairly sophisticated language in which it’s possible to write interesting programs. Each iteration of the langauge will be a strict superset of the previous one, meaning that all programs in the previous language will continue to be programs in the next language. The first iteration has nothing more that integer literals and the final iteration contains a substantial subset of Racket.
In this course, we pay particular attention to the concept of a specification, which defines what it means for our compiler to be correct. We will use testing extensively to gain some evidence that our compiler is not incorrect. Our primary goal will be in writing a correct, maintainable compiler for a full-featured language. We will not concern ourselves too much with concerns of efficiency or optimization. First things first: we have to build something that works. After that, we can think about making it work faster.
We make extensive use of writing interpreters as our form of language specification. Interpreters, when written as clear, concise code in a high-level language, provide a precise distillation of the semantics of a programming language. They can also serve as a reference implementation, used to validate other implementations of the language.
1.3 Beyond Compilers
In my opinion programming langauges are fascinating objects, worthy of study in their own right. But there are reasons beyond compilers and programming langauges for taking this class.
For any kind of craft it’s worth reflecting on the tools one uses. Doing so will make you better. It may open you up to use new tools or existing tools in new ways. It may even allow you to design and fabricate your own tools. As computer scientists, our primary expression of computational ideas comes in the form of writing programs. It’s worth reflecting on the language in which we express those ideas.
But part of what’s valuable about a course like this really has little to do with programming languages or compilers. Compilers are sophisticated artifacts. They have complex invariants and subtle specifications. Getting them right is hard. Learning how to program to a specification, to think about invariants, to write clear, concise and well-tested code is valuable beyond just writing compilers.
A function that maps an input string to an output string.
compiler : String -> String |
Typically, the input and output strings are “programs”
compiler : SourceProgram -> TargetProgram |
For example, here are some well known compilers:
gcc, clang : C -> Binary (* a.out, .exe *) |
ghc : Haskell -> Binary |
javac : Java -> JvmByteCode (* .class *) |
scalac : Scala -> JvmByteCode |
ocamlc : Ocaml -> OcamlByteCode (* .cmo *) |
ocamlopt : Ocaml -> Binary |
gwt : Java -> JavaScript (* .js *) |
v8 : JavaScript -> Binary |
nasm : x86 -> Binary |
pdftex : LaTeX -> PDF |
pandoc : Markdown -> PDF | Html | Doc |
Key Requirements on output program:
Has the same meaning (“semantics”) as input,
Is executable in relevant context (VM, microprocessor, web browser).
1.4 A Bit of History
Compilers were invented to avoid writing machine code by hand.
 From Binary to FORTRAN
From Binary to FORTRAN
Richard Hamming – The Art of Doing Science and Engineering, p25:
In the beginning we programmed in absolute binary… Finally, a Symbolic Assembly Program was devised – after more years than you are apt to believe during which most programmers continued their heroic absolute binary programming. At the time [the assembler] first appeared I would guess about 1% of the older programmers were interested in it – using [assembly] was “sissy stuff”, and a real programmer would not stoop to wasting machine capacity to do the assembly.
John A.N. Lee, Dept of Computer Science, Virginia Polytechnical Institute
One of von Neumann’s students at Princeton recalled that graduate students were being used to hand assemble programs into binary for their early machine. This student took time out to build an assembler, but when von Neumann found out about it he was very angry, saying that it was a waste of a valuable scientific computing instrument to use it to do clerical work.
1.5 What does a Compiler look like?
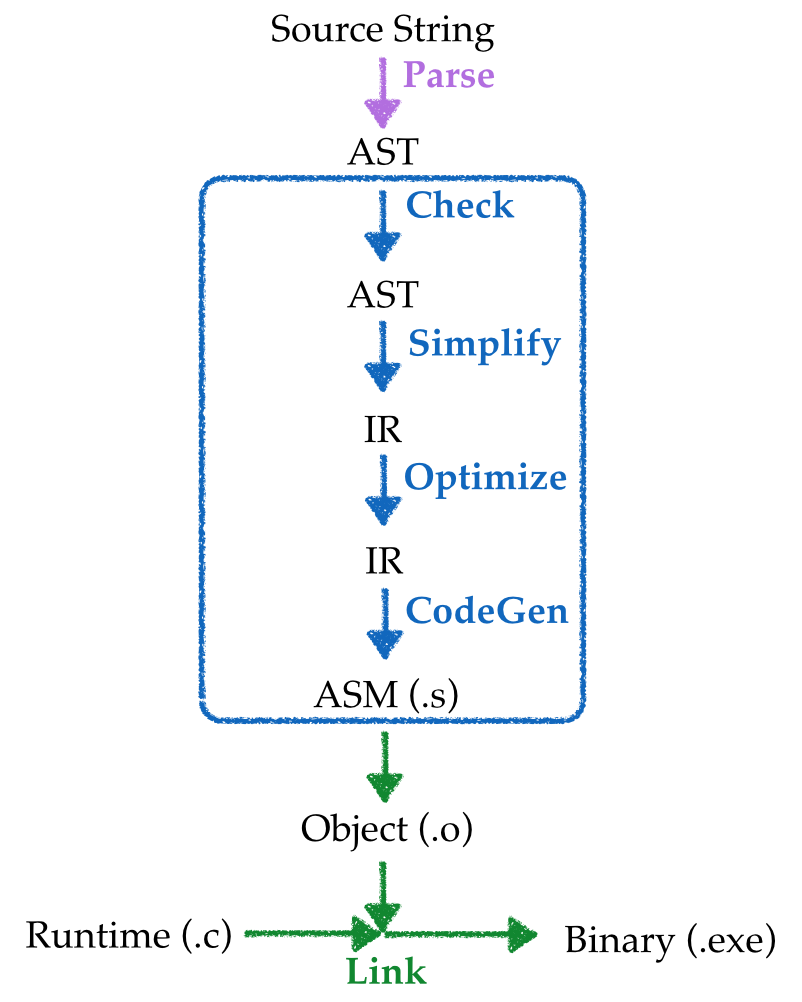 Compiler Pipeline
Compiler Pipeline
An input source program is converted to an executable binary in many stages:
Parsed into a data structure called an Abstract Syntax Tree
Checked to make sure code is well-formed (and well-typed)
Simplified into some convenient Intermediate Representation
Optimized into (equivalent) but faster program
Generated into assembly x86
Linked against a run-time (usually written in C)
1.6 What is CMSC 430?
- A bridge between two worlds
High-level programming languages: OCaml (CMSC 330)
Machine code: x86/ARM (CMSC 216)
A sequel to both those classes.
- How to write a compiler for MiniRacket -> x86
Parsing
Checking & Validation
Simplification & Normalizing
Optimization
Code Generation
- But also, how to write complex programs
Design
Implement
Test
Iterate
1.7 How to write a Compiler?
General recipe, applies to any large system
gradually, one feature at a time!
We will
Step 1 Start with a teeny tiny language,
Step 2 Build a full compiler for it,
Step 3 Add a few features,
Go to Step 2.
(Yes, loops forever, but we will hit Ctrl-C in 15 weeks...)
1.8 Mechanics
See Syllabus.
1.9 What will we do?
Write a compiler for MiniRacket -> x86
But Rome wasn’t built in a day … and neither is any serious software.
 Rome wasn’t built in a day
Rome wasn’t built in a day
So we will write many compilers:
Numbers and increment/decrement
Local Variables
Nested Binary Operations
Booleans, Branches and Dynamic Types
Functions
Tuples and Structures
Lambdas and closures
Types and Inference
Garbage Collection
1.10 What will you learn?
Core principles of compiler construction
Managing Stacks & Heap
Type Checking
Intermediate forms
Optimization
Several new languages
Racket to write the compiler
C to write the “run-time”
x86 compilation target
More importantly how to write a large program
How to use types for design
How to add new features / refactor
How to test & validate
1.11 What do you need to know?
This 430 depends very heavily on CMSC 330.
Familiarity with Functional Programming and Ocaml
Datatypes (e.g. Lists, Trees, ADTs)
Polymorphism
Recursion
Higher-order functions (e.g. map, filter, fold)
Also depends on CMSC 216
Experience with some C programming
Experience with some assembly (x86)
1.12 A few words on the medium of instruction
We will use Racket which, for our purposes is like Ocaml but with nicer syntax.1
Racket has many advanced features beyond what you saw in 330, but we won’t be using them; in the few cases we do, I’ll explain them as we go.
1To start a good flamewar just post this anywhere online where Haskell and OCaml folks can see it.