8 Dupe: a duplicity of types
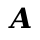
There are 10 types of values...
8.1 Integers and Booleans
Up until now we have worked to maintain a single type of values: integers. This led to some awkwardness in the design of conditionals. Let us lift this restriction by considering a multiplicity of types. To start, we will consider two: integers and booleans.
We’ll call it Dupe.
We will use the following syntax, which relaxes the syntax of Con to make (zero? e) its own expression form and conditionals can now have arbitrary expressions in test position: (if e0 e1 e2) instead of just (if (zero? e0) e1 e2). We also add syntax for boolean literals.
Together this leads to the following grammar for concrete Dupe.
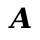
And abstract Dupe:
#lang racket (provide Lit Prim1 If) ;; type Expr = (Lit Datum) ;; | (Prim1 Op1 Expr) ;; | (If Expr Expr Expr) ;; type Datum = Integer ;; | Boolean ;; type Op1 = 'add1 | 'sub1 ;; | 'zero? (struct Lit (d) #:prefab) (struct Prim1 (p e) #:prefab) (struct If (e1 e2 e3) #:prefab)
The s-expression parser is defined as follows:
#lang racket (provide parse) (require "ast.rkt") ;; S-Expr -> Expr (define (parse s) (match s [(? datum?) (Lit s)] [(list-rest (? symbol? k) sr) (match k [(? op1? o) (match sr [(list s1) (Prim1 o (parse s1))] [_ (error "op1: bad syntax" s)])] ['if (match sr [(list s1 s2 s3) (If (parse s1) (parse s2) (parse s3))] [_ (error "if: bad syntax" s)])] [_ (error "parse error" s)])] [_ (error "parse error" s)])) ;; Any -> Boolean (define (datum? x) (or (exact-integer? x) (boolean? x))) (define (op1? x) (memq x '(add1 sub1 zero?)))
Examples
> (parse '#t) '#s(Lit #t)
> (parse '(if #t 1 2)) '#s(If #s(Lit #t) #s(Lit 1) #s(Lit 2))
> (parse '(zero? 8)) '#s(Prim1 zero? #s(Lit 8))
> (parse '(if (zero? 8) 1 2))
'#s(If
#s(Prim1 zero? #s(Lit 8))
#s(Lit 1)
#s(Lit 2))
8.2 Meaning of Dupe programs
To consider the meaning of Dupe programs, we must revisit the meaning of conditions. Previously we branched on whether a subexpression evaluated to 0. We will now consider whether the subexpression evaluates to #f.
Let’s consider some examples:
(if #f 1 2) means 2 since the test expression means #f.
(if #t 1 2) means 1 since the test expression means #t, which is not #f.
Just as in Racket (and Scheme, generally), we will treat any non-#f value as “true.” So:
(if 0 1 2) means 1 since the test expression means 0, which is not #f.
(if 7 1 2) means 1 since the test expression means 7, which is not #f.
The new (zero? e) expression form evaluates to a boolean: #t when e evaluates to 0 and #f to an integer other than 0.
The #t and #f literals mean themselves, just like integer literals.
Once a multiplicity of types are introduced, we are forced to come to grips with type mismatches. For example, what should (add1 #f) mean?
Languages adopt several approaches:
Prohibit such programs statically with a type system (e.g. OCaml, Java)
Coerce values to different types (e.g. JavaScript)
Signal a run-time error (e.g. Racket)
Leave the behavior unspecified (e.g. Scheme, C)
We are going to start by taking the last approach. Later we can reconsider the design, but for now this is a simple approach.
The interpreter follows a similar pattern to what we’ve done so far, although notice that the result of interpretation is now a Value: either a boolean or an integer:
#lang racket (provide interp) (require "../syntax/ast.rkt") (require "interp-prim.rkt") ;; type Value = ;; | Integer ;; | Boolean ;; Expr -> Value (define (interp e) (match e [(Lit d) d] [(Prim1 p e) (interp-prim1 p (interp e))] [(If e1 e2 e3) (if (interp e1) (interp e2) (interp e3))]))
The interpretation of primitives is extended to account for the new zero? primitive:
dupe/interpreter/interp-prim.rkt
#lang racket (provide interp-prim1) ;; Op1 Value -> Value (define (interp-prim1 op v) (match op ['add1 (add1 v)] ['sub1 (sub1 v)] ['zero? (zero? v)]))
We can confirm the interpreter computes the right result for the examples given earlier:
Examples
> (interp (parse #t)) #t
> (interp (parse #f)) #f
> (interp (parse '(if #f 1 2))) 2
> (interp (parse '(if #t 1 2))) 1
> (interp (parse '(if 0 1 2))) 1
> (interp (parse '(if 7 1 2))) 1
> (interp (parse '(if (zero? 7) 1 2))) 2
8.3 (Lack of) Meaning for some Dupe programs
Viewed as a specification, what is this interpreter saying about programs that do nonsensical things like (add1 #f)?
Consider the beginning of the correctness statement:
Compiler Correctness: For all e ∈ Expr and v ∈ Value, if (interp e) equals v, then ...
Now, the thing to notice here is that this specification only obligates the compiler to produce a result consistent with the interpreter when the interpreter produces a value. It says nothing about what the compiler must produce if the intepreter fails to produce a value, which is exactly what happens when the interpreter is run on examples like (add1 #f):
Examples
> (interp (parse '(add1 #f))) add1: contract violation
expected: number?
given: #f
Since the intepreter does not return a value on such an input, the meaning of such expression is undefined and the compiler is unconstrained and may do whatever it likes: crash at compile-time, crash at run-time, return 7, format your hard drive; there are no wrong answers. (These possibilities hopeful make clear while undefined behavior opens up all kinds of bad outcomes and has been the source of many costly computing failures and vulnerabilities and why as a language designer, leaving the behavior of some programs undefined may not be a great choice. As a compiler implementor, however, it makes our life easier: we simply don’t need to worry about what happens on these kinds of programs.)
This will, however, complicate testing the correctness of the compiler, which is addressed in Correctness and testing.
Let’s now turn to the main technical challenge introduced by the Dupe langauge.
8.4 Ex uno plures: Out of One, Many
Before getting in to the compiler, let’s first address the issue of representation of values in the setting of a86.
So far we’ve had a single type of value: integers. Luckily, a86 has a convenient datatype for representing integers: it has 64-bit integers. (There is of course the problem that this representation is inadequate; there are many (Con) integers we cannot represent as a 64-bit integer. But we put off worrying about this until later.)
The problem now is how to represent integers and booleans, which should be disjoint sets of values. Representing these things in the interpreter as Racket values was easy: we used Racket booleans to represent Dupe booleans; we used Racket integers to represent Dupe integers. Since Racket booleans and integers are disjoint types, everything was easy and sensible.
Representing this things in a86 will be more complicated. a86 doesn’t have a notion of “boolean” per se and it doesn’t have a notion of “disjoint” datatypes. There is only one data type and that is: bits.
To make the problem concrete, consider the Dupe expression 5; we know the compiler is going to emit an single instruction that moves this value into the rax register:
Examples
> (Mov rax 5) (Mov 'rax 5)
But now consider #t. The compiler needs to emit an instruction that moves “#t” into rax, but the Mov instruction doesn’t take booleans:
Examples
> (Mov rax #t) Mov: expects register, offset, or expression; given #t
We have to move some 64-bit integer into rax, but the question is: which one?
The immediate temptation is to just pick a couple of integers: one for representing #t and one for #f. We could follow the C tradition and say #f will be 0 and #t will be 1. So compiling #t would emit:
Examples
> (Mov rax 1) (Mov 'rax 1)
And compiling #f would emit:
Examples
> (Mov rax 0) (Mov 'rax 0)
Seems reasonable. Well except that the specification of if in our interpreter requires that (if 0 1 2) evaluates to 1 and (if #f 1 2) evaluates to 2. But notice that 0 and #f compile to exactly the same thing under the above scheme. How could the code emitted for if possibly distinguish between whether the test expression produced #f or 0 if they are represented by the same bits?
So the compiler is doomed to be incorrect on some expressions under this scheme. Maybe we should revise our choice and say #t will be represented as 0 and #f should be 1, but now the compiler must be incorrect either on (if #f 1 2) or (if 1 1 2). We could choose different integers for the booleans, but there’s no escaping it: just picking some bits for #t and #f without also changing the representation of integers is bound to fail.
Here’s another perspective on the same problem. Our compiler emits code that leaves the value of an expression in the rax register, which is how the value is returned to the run-time system that then prints the result. Things were easy before having only integers: the run-time just prints the integer. But with booleans, the run-time will need to print either #t or #f if the result is the true or false value. But if we pick integers to represent #t, how can the run-time know whether it should print the result as an integer or as #t? It can’t!
The fundamental problem here is that according to our specification, interp, these values need to be disjoint. No value can be both an integer and a boolean. Yet in x86 world, only one kind of thing exists: bits, so how can we make values of different kinds?
Ultimately, the only solution is to incorporate an explicit representation of the type of a value and use this information to distinguish between values of different type. We could do this in a number of ways: we could desginate another register to hold (a representation of) the type of the value in rax. This would mean you couldn’t know what the value in rax meant without consulting this auxiliary register. In essence, this is just using more than 64-bits to represent values. Alternatively, we could instead encode this information within the 64-bits so that only a single register is needed to completely determine a value. This does come at a cost though: if some bits are needed to indicate the type, there are fewer bits for the values!
Here is the idea of how this could be done: We have two kinds of data: integers and booleans, so we could use one bit to indicate whether a value is a boolean or an integer. The remaining 63 bits can be used to represent the value itself, either true, false, or some integer. There are other approaches to solving this problem, but this is a common approach called type-tagging.
Let’s use the least significant bit to indicate the type and let’s use #b0 for integer and #b1 for boolean. These are arbitrary choices (more or less).
The number 1 would be represented as #b10, which is the bits for the number (i.e. #b1), followed by the integer tag (#b0). Note that the representation of a Dupe number is no longer the number itself: the Dupe value 1 is represented by the number 2 (#b10). The Dupe value #t is represented by the number 1 (#b01); the Dupe value #f is represented by the number 3 (#b11).
One nice thing about our choice of encoding: 0 is represented as 0 (#b00).
To encode a value as bits:
If the value is an integer, shift the value to the left one bit. (Mathematically, this has the effect of doubling the number.)
- If the value is a boolean,
if it’s the boolean #t, encode as 1,
if it’s the value #f, encode as 3.
To decode bits as a value:
If the least significant bit is 0, shift to the right one bit. (Mathematically, this has the effect of halving the number.)
If the bits are 1, decode to #t.
If the bits are 3, decode to #f.
All other bits don’t encode a value.
If you wanted to determine if a 64-bit integer represented an integer value or a boolean value, you simply need to inquire about the value of the least significant bit. Mathematically, this just corresponds to asking if the number is even or odd. Odd numbers end in the bit (#b1), so they reprepresent booleans. Even numbers represent integers. Here are some functions to check our understanding of the encoding:
#lang racket (provide (all-defined-out)) (define int-shift 1) (define mask-int #b1) (define type-int #b0) ;; Value -> Integer (define (value->bits v) (cond [(eq? v #t) #b01] [(eq? v #f) #b11] [(integer? v) (arithmetic-shift v int-shift)])) (define (int-bits? v) (= type-int (bitwise-and v mask-int)))
Examples
> (bits->value 0) 0
> (bits->value 1) #t
> (bits->value 2) 1
> (bits->value 3) #f
> (bits->value 4) 2
> (bits->value 5) invalid bits
> (bits->value 6) 3
> (bits->value 7) invalid bits
Notice that not all bits represent a value; name any odd number that’s neither 1 (#f) or 3 (#t).
We can also write the inverse:
Examples
> (value->bits #t) 1
> (value->bits #f) 3
> (value->bits 0) 0
> (value->bits 1) 2
> (value->bits 2) 4
> (value->bits 3) 6
> (bits->value (value->bits #t)) #t
> (bits->value (value->bits #f)) #f
> (bits->value (value->bits 0)) 0
> (bits->value (value->bits 1)) 1
> (bits->value (value->bits 2)) 2
> (bits->value (value->bits 3)) 3
The interpreter operates at the level of Values. The compiler will have to work at the level of Bits.
8.5 An Example of Dupe compilation
The most significant change from Con to Dupe for the compiler is the change in representation of values.
Let’s consider some simple examples:
42: this should compile just like integer literals before, but needs to use the new representation, i.e. the compiler should produce (Mov rax 84), which is 42 shifted to the left 1-bit.
(add1 e): this should produce the instructions for e, which when executed would leave the encoding of the value of e in the rax register. To these instructions, the compiler needs to append instructions that will leave the encoding of one more than the value of e in rax. In other words, it should add 2 to rax!
(zero? e): this should produce the instructions for e followed by instructions that compare rax to the encoding of the value 0, which is just the bits 0, and set rax to #t (i.e. #b01) if true and #f (i.e. #b11) otherwise.
This is a bit different from what we saw with Con, which combined conditional execution with testing for equality to 0. Here there is no need to jump anywhere based on whether e produces 0 or not. Instead we want to move either the encoding of #t or #f into rax depending on what e produces. To accomplish that, we can use a new kind of instruction, the conditional move instruction: Cmov.
(if e0 e1 e2): this should work much like before, compiling each subexpression, generating some labels and the appropriate comparison and conditional jump. The only difference is we now want to compare the result of executing e0 with (the encoding of the value) #f (i.e. #b11) and jumping to the code for e2 when they are equal.
Examples
> (compile-e (Lit 42)) (list (Mov 'rax 84))
> (compile-e (Lit #t)) (list (Mov 'rax 1))
> (compile-e (Lit #f)) (list (Mov 'rax 3))
> (compile-e (parse '(zero? 0)))
(list
(Mov 'rax 0)
(Cmp 'rax 0)
(Mov 'rax 3)
(Mov 'r9 1)
(Cmove 'rax 'r9))
> (compile-e (parse '(if #t 1 2)))
(list
(Mov 'rax 1)
(Cmp 'rax 3)
(Je 'if7023)
(Mov 'rax 2)
(Jmp 'if7024)
(Label 'if7023)
(Mov 'rax 4)
(Label 'if7024))
> (compile-e (parse '(if #f 1 2)))
(list
(Mov 'rax 3)
(Cmp 'rax 3)
(Je 'if7025)
(Mov 'rax 2)
(Jmp 'if7026)
(Label 'if7025)
(Mov 'rax 4)
(Label 'if7026))
8.6 A Compiler for Dupe
Based on the examples, we can write the compiler. Notice that the compiler uses the value->bits function we wrote earlier for encoding values as bits. This helps make the code more readable and easier to maintain should the encoding change in the future. But it’s important to note that this function is used only at compile-time. By the time the assemble code executes (i.e. run-time) the value->bits function (and indeed all Racket functions) no longer exists.
#lang racket (provide compile compile-e) (require "../syntax/ast.rkt") (require "compile-ops.rkt") (require "../runtime/types.rkt") (require a86/ast a86/registers) ;; Expr -> Asm (define (compile e) (prog (Global 'entry) (Label 'entry) (compile-e e) (Ret))) ;; Expr -> Asm (define (compile-e e) (match e [(Lit d) (compile-datum d)] [(Prim1 p e) (compile-prim1 p e)] [(If e1 e2 e3) (compile-if e1 e2 e3)])) ;; Datum -> Asm (define (compile-datum d) (seq (Mov rax (value->bits d)))) ;; Op1 Expr -> Asm (define (compile-prim1 p e) (seq (compile-e e) (compile-op1 p))) ;; Expr Expr Expr -> Asm (define (compile-if e1 e2 e3) (let ((l1 (gensym 'if)) (l2 (gensym 'if))) (seq (compile-e e1) (Cmp rax (value->bits #f)) (Je l1) (compile-e e2) (Jmp l2) (Label l1) (compile-e e3) (Label l2))))
The compilation of primitives, including the new zero? primitive, can be accomplished with:
#lang racket (provide compile-op1) (require "../syntax/ast.rkt") (require "../runtime/types.rkt") (require a86/ast a86/registers) ;; Op1 -> Asm (define (compile-op1 p) (match p ['add1 (Add rax (value->bits 1))] ['sub1 (Sub rax (value->bits 1))] ['zero? (seq (Cmp rax 0) (Mov rax (value->bits #f)) (Mov r9 (value->bits #t)) (Cmove rax r9))]))
We can try out the compiler with the help of asm-interp, but you’ll notice the results are a bit surprising:
Examples
> (asm-interp (compile (Lit #t))) 1
> (asm-interp (compile (Lit #f))) 3
> (asm-interp (compile (parse '(zero? 0)))) 1
> (asm-interp (compile (parse '(zero? -7)))) 3
> (asm-interp (compile (parse '(if #t 1 2)))) 2
> (asm-interp (compile (parse '(if #f 1 2)))) 4
> (asm-interp (compile (parse '(if (zero? 0) (if (zero? 0) 8 9) 2)))) 16
> (asm-interp (compile (parse '(if (zero? (if (zero? 2) 1 0)) 4 5)))) 8
The reason for this is asm-interp doesn’t do any interpretation of the bits it gets back; it is simply producing the integer that lives in rax when the assembly code finishes. This suggests adding a call to bits->value can be added to interpret the bits as values:
Examples
> (bits->value (asm-interp (compile (Lit #t)))) #t
Which leads us to the following definition of exec:
#lang racket (provide run exec) (require a86/interp) (require "../compiler/compile.rkt") (require "decode.rkt") ;; Asm -> Value (define (run asm) (bits->value (asm-interp asm))) ;; Expr -> Value (define (exec e) (run (compile e)))
Examples
> (exec (parse #t)) #t
> (exec (parse #f)) #f
> (exec (parse '(zero? 0))) #t
> (exec (parse '(zero? -7))) #f
> (exec (parse '(if #t 1 2))) 1
> (exec (parse '(if #f 1 2))) 2
> (exec (parse '(if (zero? 0) (if (zero? 0) 8 9) 2))) 8
> (exec (parse '(if (zero? (if (zero? 2) 1 0)) 4 5))) 4
The one last peice of the puzzle is updating the run-time system to incorporate the new representation. The run-time system is essentially playing the role of bits->value: it determines what is being represented and prints it appropriately.
8.7 Correctness and testing
We already established our definition of correctness:
Compiler Correctness: For all e ∈ Expr and v ∈ Value, if (interp e) equals v, then (exec e) equals v.
As a starting point for testing, we can consider a revised version of check-compiler that also uses bits->value:
Examples
> (define (check-compiler* e) (check-equal? (interp e) (exec e)))
This works just fine for meaningful expressions:
Examples
> (check-compiler* (parse #t)) > (check-compiler* (parse '(add1 5))) > (check-compiler* (parse '(zero? 4))) > (check-compiler* (parse '(if (zero? 0) 1 2)))
But, as discussed earlier, the hypothetical form of the compiler correctness statement is playing an important role: if the interpreter produces a value, the compiler must produce code that when run produces the (representation of) that value. But if the interpeter does not produce a value, all bets are off.
From a testing perspective, this complicates how we use the interpreter to test the compiler. If every expression has a meaning according to interp (as in all of our previous languages), it follows that the interpreter cannot crash on any Expr input. That makes testing easy: think of an expression, run the interpreter to compute its meaning and compare it to what running the compiled code produces. But now the interpreter may break if the expression is undefined. We can only safely run the interpreter on expressions that have a meaning.
This means the above definition of check-compiler won’t suffice, because this function crashes on inputs like (add1 #f), even though such an example doesn’t actually demonstrate a problem with the compiler:
Examples
> (check-compiler* (parse '(add1 #f)))
--------------------
ERROR
name: check-equal?
location: eval:184:0
add1: contract violation
expected: number?
given: #f
--------------------
To overcome this issue, we can take advantage of Racket’s exception handling mechanism to refine the check-compiler function:
#lang racket (provide check-compiler) (require rackunit) (require "interpreter/interp.rkt") (require "executor/exec.rkt") ;; Expr -> Void (define (check-compiler e) (let ((r (with-handlers ([exn:fail? identity]) (interp e)))) (unless (exn? r) (check-equal? r (exec e)))))
This version installs an exception handler around the call to interp and in case the interpreter raises an exception (such as when happens when interpreting (add1 #f)), then the handler simply returns the exception itself.
The function then guards the check-equal? test so that the test is run only when the result was not an exception. (It’s important that the compiler is not run within the exception handler since we don’t want the compiler crashing to circumvent the test: if the interpreter produces a value, the compiler is not allowed to crash!)
We can confirm that the compiler is still correct on meaningful expressions:
Examples
> (check-compiler (parse #t)) > (check-compiler (parse #f)) > (check-compiler (parse '(if #t 1 2))) > (check-compiler (parse '(if #f 1 2))) > (check-compiler (parse '(if 0 1 2))) > (check-compiler (parse '(if 7 1 2))) > (check-compiler (parse '(if (zero? 7) 1 2)))
Examples
> (exec (parse '(add1 #f))) invalid bits
> (exec (parse '(if (zero? #t) 7 8))) 8
Yet these are not counter-examples to the compilers correctness:
Examples
> (check-compiler (parse '(add1 #f))) > (check-compiler (parse '(if (zero? #t) 7 8)))
With this set up, we can randomly generate Dupe programs and throw them at check-compiler. Many randomly generated programs will have type errors in them, but with our revised version check-compiler, it won’t matter (although it’s worth thinking about how well this is actually testing the compiler).
Examples
> (require "syntax/random.rkt") > (random-expr) '#s(Lit 3)
> (random-expr) '#s(Prim1 sub1 #s(Lit #t))
> (random-expr) '#s(Prim1 sub1 #s(Prim1 zero? #s(Lit 2)))
> (random-expr)
'#s(Prim1
zero?
#s(Prim1 add1 #s(Prim1 zero? #s(Lit -6))))
> (random-expr) '#s(Lit #f)
> (random-expr)
'#s(If
#s(Prim1 zero? #s(Lit #f))
#s(Prim1
zero?
#s(If
#s(Lit #f)
#s(If #s(Lit #t) #s(Lit 4) #s(Lit #t))
#s(Prim1 add1 #s(Lit #f))))
#s(Lit 6))
> (for ([i (in-range 10)]) (check-compiler (random-expr)))
8.8 Updated stand-alone run-time system
We saw in Abscond: a language of numbers that if want to make a stand-alone executable, i.e. if we want to compile programs into executables that do not depend on the host language, we need to provide a small support library that is linked with every compiled program. This is called the run-time system.
Any time there’s a change in the representation or set of values, there’s going to be a required change in the run-time system. From Abscond through Con, there were no such changes, but now we have to udpate our run-time system to reflect the changes made to values in Dupe.
One of the responsibilities of the run-time system is printing the final result of computation, so the run-time system, like bits->value, needs to be able to determine the kind of value the return bits represent so it can print appropriately.
We define the bit representations in a header file corresponding to the definitions given in types.rkt:
#ifndef TYPES_H #define TYPES_H /* Bit layout of values Values are either: - Integers: end in #b0 - True: #b01 - False: #b11 */ #define int_shift 1 #define int_type_mask ((1 << int_shift) - 1) #define int_type_tag (0 << (int_shift - 1)) #define nonint_type_tag (1 << (int_shift - 1)) #define val_true ((0 << int_shift) | nonint_type_tag) #define val_false ((1 << int_shift) | nonint_type_tag) #endif
It uses an idiom of “masking” in order to examine on particular bits of a value. So for example if we want to know if the returned value is an integer, we do a bitwise-and of the result and 1. This produces a single bit: 0 for integer and 1 for boolean. In the case of an integer, to recover the number being represented, we need to divide by 2, which can be done efficiently with a right-shift of 1 bit. Likewise with a boolean, if we shift right by 1 bit there are two possible results: 3 for false and 1 for true.
We use the following interface for values in the runtime system:
#ifndef VALUES_H #define VALUES_H #include <stdint.h> /* any abstract value */ typedef int64_t val_t; typedef enum type_t { T_INVALID = -1, /* immediates */ T_INT, T_BOOL, } type_t; /* return the type of x */ type_t val_typeof(val_t x); /** * Wrap/unwrap values * * The behavior of unwrap functions are undefined on type mismatch. */ int64_t val_unwrap_int(val_t x); val_t val_wrap_int(int64_t i); int val_unwrap_bool(val_t x); val_t val_wrap_bool(int b); #endif
#include "types.h" #include "values.h" type_t val_typeof(val_t x) { if ((int_type_mask & x) == int_type_tag) return T_INT; switch (x) { case val_true: case val_false: return T_BOOL; } return T_INVALID; } int64_t val_unwrap_int(val_t x) { return x >> int_shift; } val_t val_wrap_int(int64_t i) { return (i << int_shift) | int_type_tag; } int val_unwrap_bool(val_t x) { return x == val_true; } val_t val_wrap_bool(int b) { return b ? val_true : val_false; }
The main function remains largely the same although now we use val_t in place of int64_t:
#include <stdio.h> #include "values.h" #include "print.h" val_t entry(); int main(int argc, char** argv) { val_t result = entry(); print_result(result); putchar('\n'); return 0; }
And finally, print_result is updated to do a case analysis on the type of the result and print accordingly:
#include <stdio.h> #include <inttypes.h> #include "values.h" void print_result(val_t x) { switch (val_typeof(x)) { case T_INT: printf("%" PRId64, val_unwrap_int(x)); break; case T_BOOL: printf(val_unwrap_bool(x) ? "#t" : "#f"); break; case T_INVALID: printf("internal error"); } }
We can now make an example and compile it into a standalone executable.
shell
> printf "#lang racket\n#t" | \ racket -t compiler/compile-stdin.rkt -m > true.s > clang -c true.s > make -C runtime make[1]: Entering directory '/home/runner/work/cmsc430.github.io/cmsc430.github.io/langs/dupe/runtime' clang -g -c -o main.o main.c clang -g -c -o print.o print.c clang -g -c -o values.o values.c ld -r main.o print.o values.o -o runtime.o make[1]: Leaving directory '/home/runner/work/cmsc430.github.io/cmsc430.github.io/langs/dupe/runtime' > clang true.o runtime/runtime.o -o true /usr/bin/ld: warning: true.o: missing .note.GNU-stack section implies executable stack /usr/bin/ld: NOTE: This behaviour is deprecated and will be removed in a future version of the linker
Here we are taking advantage of a Makefile provided to build the runtime system. Then we link it with the object code for the Racket program. Finally we can run the executable:
shell
> ./true #t